The code for the hackathon project is available on GitHub
Summary
When AI becomes fast enough, computing itself changes. Cerebras OS is a hackathon project exploring what happens when inference speed crosses a threshold—when AI stops being something you wait for and becomes something you interact with.
A New Threshold
We’re used to designing around AI latency. You build your UI, add a loading spinner, send a request to the AI, and eventually get back a response. This pattern has shaped how we think about AI-powered applications: the AI is always somewhere else, always asynchronous, always a step removed from the interaction.
But what if it wasn’t? What if AI inference was so fast that it could live inside the interaction loop itself?
That’s the question I set out to explore with Cerebras OS. Using Cerebras’ ultra-fast inference through OpenRouter, I built an interface where every interaction—every click, every widget request, every UI update—flows through an LLM in real-time. Not as a background process. Not with loading states. Just immediate, responsive, and always there.
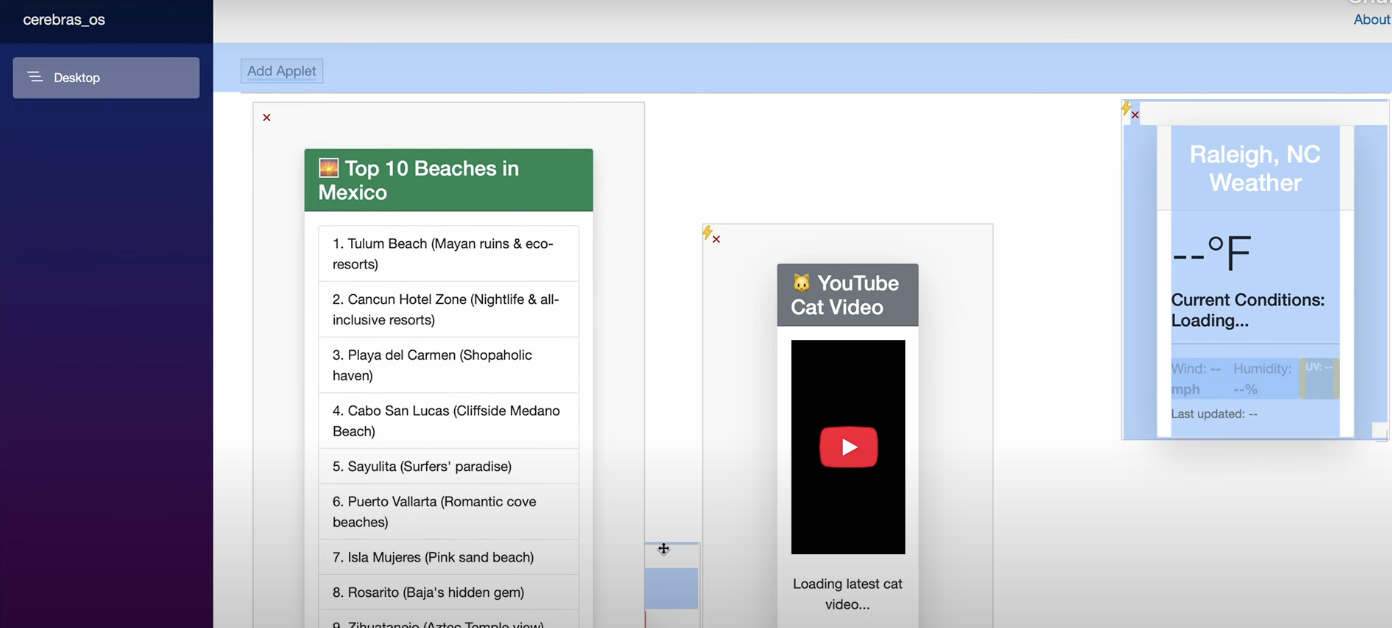
The Demo: Widgets as a Proof of Concept
The interface I built uses widgets—small, dynamic components that can display anything from weather to task lists. But the widgets themselves aren’t the point. They’re just a way to demonstrate something more fundamental: when AI is fast enough, you can stop pre-programming your interface and start generating it on demand.
Ask for a weather widget, and the AI creates one instantly. It generates the HTML, decides on the styling, pulls in live data, and updates it in real-time. Want something different? Just ask. The AI adapts, evolves, and responds without you ever feeling like you’re waiting for a machine to think.
This isn’t about making better widgets. It’s about what becomes possible when you can put an LLM directly in the decision-making path of your UI. Every interaction becomes an opportunity for the software to be smarter, more contextual, more adaptive—not because you pre-programmed those paths, but because the AI can make those decisions in the moment.
Why Speed Matters: A Paradigm Shift
We spend a lot of time talking about AI capabilities—what models can do, what tasks they can solve, what benchmarks they can pass. But speed is different. Speed isn’t just about doing the same things faster; it unlocks entirely new ways of building software.
When Cerebras can return responses in under a second, consistently, something shifts. The AI stops being a tool you call and becomes something more fundamental—a layer of intelligence woven into the fabric of your application. You stop designing around it and start designing with it.
In traditional software, you anticipate user needs and pre-build flows for every scenario. With fast AI, you can generate those flows on demand. The interface becomes fluid, adaptive, personal—not because you wrote a thousand if-statements, but because the AI can understand context and respond in real-time.
This is the real promise of Cerebras OS, and projects like it. They’re not about widgets or chat interfaces or any specific feature. They’re about exploring what computing looks like when intelligence is synchronous with interaction.
Building It
I built this using Blazor Server and .NET 8 for real-time WebSocket connections, with qwen3-32b running on Cerebras hardware through OpenRouter. The model was chosen for its speed and ability to output structured JSON—critical for generating consistent, usable HTML.
The architecture is deliberately simple: route everything through the AI. In most systems, this would be a terrible idea. But when your inference is fast enough, simplicity becomes viable. You don’t need complex caching strategies or pre-computation. You just ask the AI what to do next.
There’s also a background processing system that pulls in context from the web using OpenRouter’s search capabilities, enriching the AI’s responses without impacting the interaction speed. But the core insight remains: when AI is fast, your architecture can be fundamentally different.
The Bigger Picture
This project is aspirational. It’s not a production system; it’s a sketch of what could be. Just like early flight demonstrations weren’t about the specific aircraft but about proving that flight was possible, Cerebras OS is about proving that synchronous AI-powered interfaces are possible.
We’re at the beginning of a shift. As inference speeds continue to improve, we’ll see new categories of software that simply couldn’t exist before:
- Interfaces that adapt in real-time to user intent without explicit programming
- Applications that generate their own UI based on context and conversation
- Systems where the boundary between “the application” and “the AI” dissolves entirely
The widgets in this demo are just placeholders. Tomorrow it might be entire application flows generated on demand. The day after, interfaces that evolve as you use them. The underlying principle remains: when AI is fast enough to be synchronous, computing enters a new paradigm.
We’re still years away from seeing this widely deployed. Infrastructure needs to be built. Patterns need to be discovered. Costs need to come down. But the threshold has been crossed. Fast AI isn’t just faster AI—it’s a different kind of tool entirely.
Try It Yourself
The code is on GitHub if you want to explore. You’ll need an OpenRouter API key:
1
2
export OPENROUTER_API_KEY=your_key_here
dotnet run
Play with it. Break it. Imagine what else could be built if AI was always this fast. That’s the real point of projects like this—not what they are, but what they help us imagine.
 Want to work with me? Send me an email.
Want to work with me? Send me an email.